 EN
EN  PT-BR
PT-BR FR
FR ES
ES DE
DE
The introduction of ChatGPT and Bard has changed how customers look for information. Generative Artificial Intelligence (GenAI) technology is setting a new trend in how information is being consumed in this AI-first era. Customers seek accurate information for their questions/prompts by utilizing the power of GenAI tools.
The GenAI technology is built on top of Large Language Models (LLMs), which are trained using a large corpus of text data available on the internet. Many vendors, such as OpenAI, Anthrophic, and others, have proprietary LLMs available through APIs. Some vendors, such as Meta, have fully open sources for their LLMs. The LLMs and their associated APIs play a huge role in building an assistive search engine that is powered by GenAI capabilities.
The problem with LLMs is that they cannot provide any recent or present information as they need months to retrain with new data. To overcome this limitation, an innovative architecture is proposed that sits on top of LLMs.
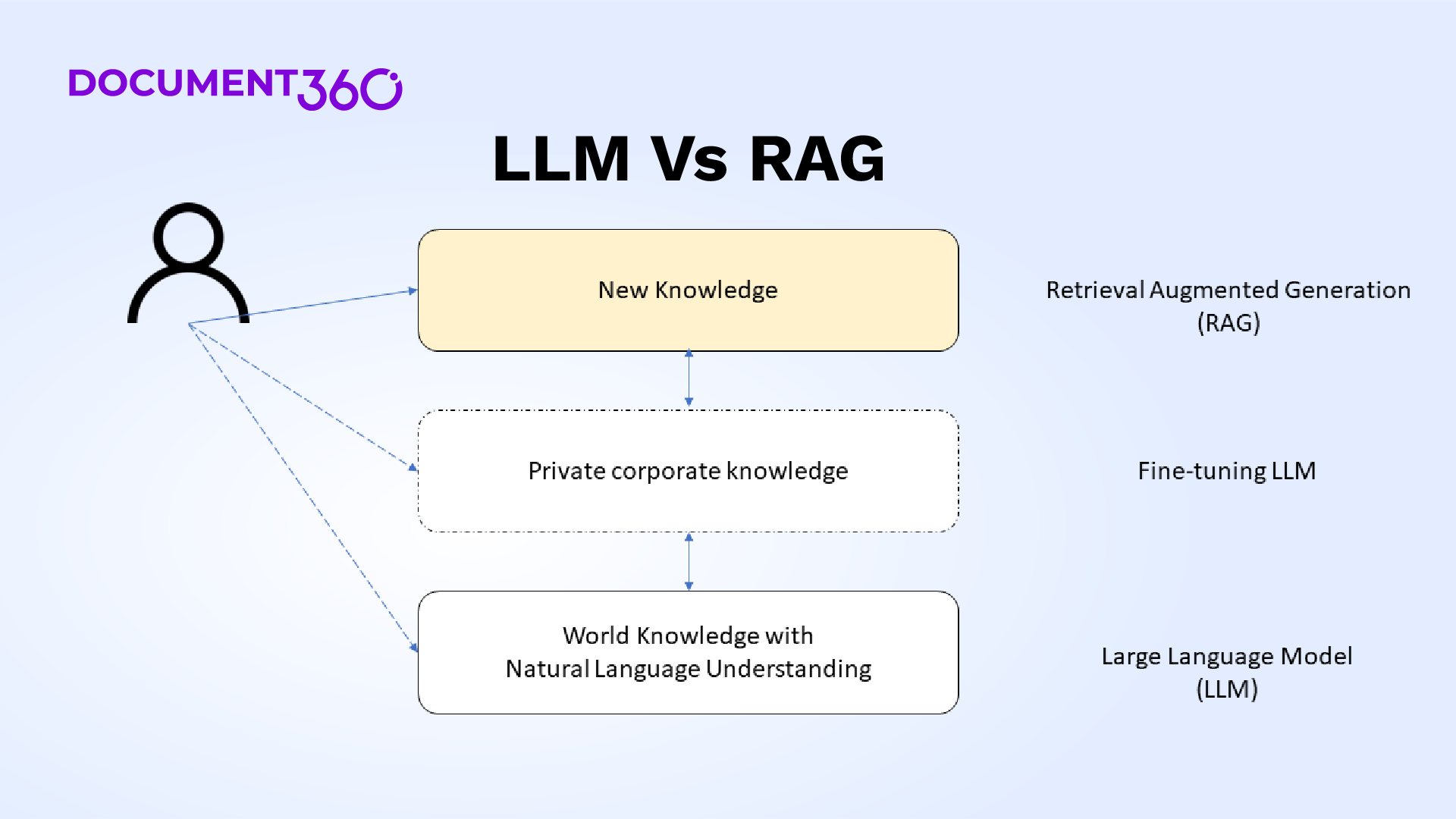
What is the Retrieval Augmented Generation (RAG) framework?
The Retrieval Augmented Generation (RAG) is an elegant way to augment recent or new information to be presented to the underlying LLMs such that it can understand the question that seeks new information. The RAG framework powers all the GenAI-based search engines or any search engine that provides context-aware answers to customers’ questions.
RAG architecture
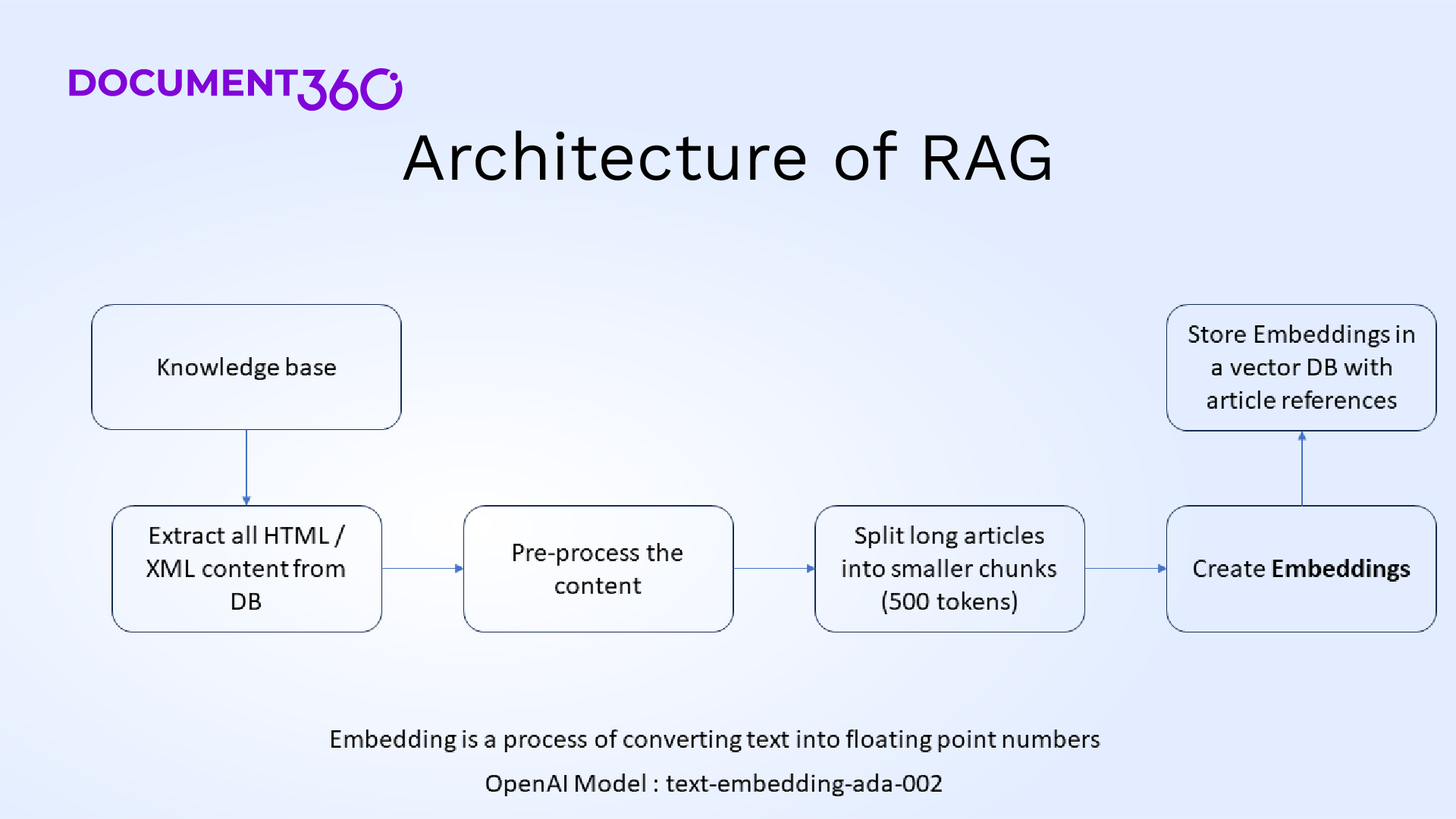
The RAG architecture consists of a Retriever Module and a Generator Module. For RAG architecture to work, we need to chunk all the knowledge base content into small chunks. There are many ways to chunk all the knowledge base content, such as
- Chunk them based on content hierarchy
- Chunk them based on the use case
- Chunk them based on content type and use case
Once the text data is chunked, then all these chunks need to be converted into text embedding. Text embedding is a process of converting text data into numerical (floating point numbers) that captures the semantics of the text data present inside the chunk along with its information. A plethora of APIs are available from GenAI tool vendors whereby the embedding model is a popular API quickly and cheaply. OpenAI Ada text embedding model is a popular API that is widely used.
The next step in the process is to store all text embeddings along with their related chunks and metadata in a vector database.
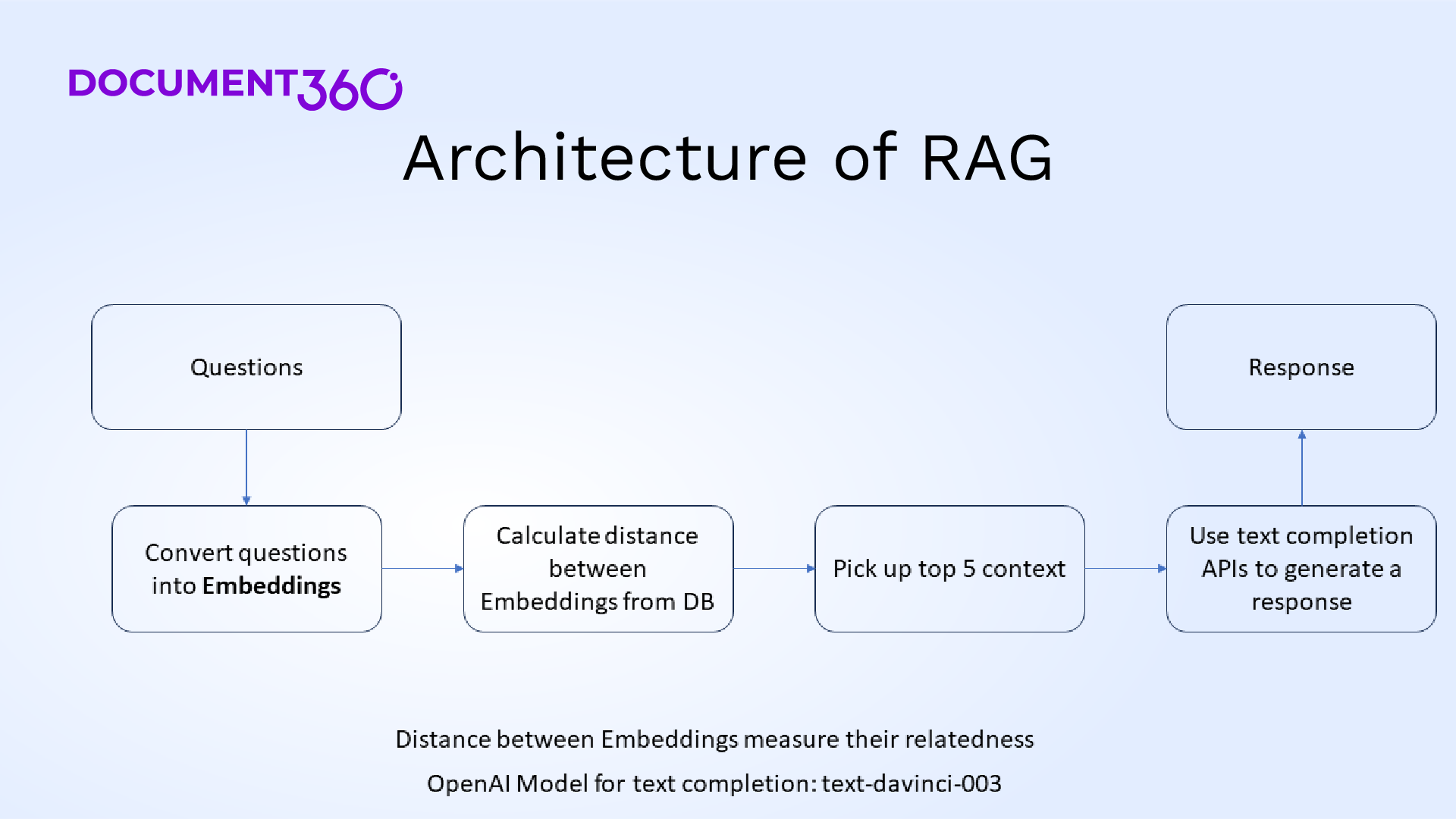
Once the customer enters the question/prompt, we convert the question into an embedding, and a vector search is performed to match embeddings from the vector database semantically. The vector search is done through Hierarchical Navigable Small Worlds (HNSW) whereby vector databases can return top contexts within a few milliseconds. The number of contexts returned is configurable, and empirically, it is chosen as 5. Semantic matching happens through similarity metrics such as cosine similarity, dot product, and Euclidean distance. Most of the time, dot product metric is used as it is like cosine similarity given that text embeddings are normalized to a value of 1. This retriever module task is to return the top 5 contexts (chunks) from the vector database. Once the top 5 contexts are returned, a response is generated using the chat completion APIs from tool vendors. The response is shown in the UI (User Interface). The top 5 contexts can be shown as citations that are used to generate this response ensuring trust. This also helps users verify the source of the article to ensure that the GenAI tool is not hallucinating!
The RAG architecture is an elegant and simple way to implement a GenAI-based search engine/chatbot on top of your technical documentation. Many vendors have released a boilerplate code that can be used out-of-the-box to implement the GenAI assistive search engine. MongoDB has open-sourced a chatbot framework. This makes it easy for many organizations to implement these GenAI capabilities on top of their knowledge base.
Also Read: Benefits of Building ChatGPT like GenAI Assistive Search for your Knowledge Base
Tips to implement GenAI search engine
These are a few tips that will help with getting the GenAI search engine set up effectively
- Ensure that the underlying knowledge base is available in HTML or markdown format
- Choose an optimal chunking strategy based on your customer persona and the questions you usually ask.
- Use any NoSQL database rather than using a dedicated vector database. Provisioning a vector database will add cost and, more importantly, comes with a lot of administrative overheads, such as
- Data sync
- Applying access control permissions for content
- Security hardening the vector database.
- Use a state-of-the-art text embedding model from the LLM vendor
- Optimize the chunk size and number of chunks returned for your use case
- Choose a good chat completion API from an available LLM vendor
- Fine-tune your system message for chat completion
- Optimize the cost, accuracy, and user experience during the design stage
- Build an intuitive interface to access the powered search engine such that customers are encouraged to use it and understand the value proposition
- Ensure all returned contexts are present in the UI so that they serve as a citation
- Experiment with various embedding and chat completion models and keep your search tool updated with recent model updates from the LLM vendor
Check out our video on Multilingual AskEddy to get instant answers in multiple languages!
Closing remarks
Many users across the world have heavily adopted the GenAI-powered search engine. The GenAI-powered search engine has been heavily adopted by many users across the world. Most B2C search engine providers, such as Google, Microsoft, and DuckDuckGo, already infuse GenAI capabilities in their lexical search engines. Many of your customers will expect the GenAI search engine on top of their documentation so that they can find answers to their questions more quickly. The RAG architecture is a popular architecture to implement GenAI-powered search engines. Optimizing chunk size and number of chunks will optimize context relevancy of your retriever module of the RAG system while fine-tuning system messages in the chat completion will optimize the quality of the generated response of your generator module. Given the shift in customer behavior, it is poised to become the default search engine for the newer generation of customers.

