 EN
EN  PT-BR
PT-BR FR
FR ES
ES DE
DE
Search engines have become an integral part of our everyday lives; Google has even become a verb in the English language. Every business, therefore, needs to pay attention to its search engine ranking. In Document360, we had recently encountered a challenge with SEO ranking. So, before we jump into the problem let us understand how crawling & rendering works.
How does Crawling and Rendering work?
A Google bot or a computer that has a list of links from our website known as ‘sitemap’ will be available on every site provided by the site owners. When the crawler finds a page, it tries to render the page like what the browser does, but without any user context.
Most of the content is rendered on the server and it is ready to be viewed by the browser on request. Server-side rendering allows for an amazingly fast experience on the site with quick initial load times and less JavaScript to be painted. But still, most applications cannot just rely on complete SSR.
Having JavaScript on the client allows us to do ‘event handling’ and run logic on the client with little to no requests to the server to perform client-side operations.
The Document360 Knowledge Base experience
All knowledge base sites have a few sections in common. These are very standard and will be available on any knowledge base site that you visit.
- Categories tree to navigate between content (left)
- Content part (middle)
- Table of contents (right)
- Search (top)
So far, we have not spoken about the actual problem yet. Recently some of our customers have started complaining that the knowledge base SEO is having an impact and the users are having trouble finding content using search engines. After our initial analysis, we have found out the mechanism in which we load the content on the page was causing an impact on the SEO.
The implementation that we had to fetch the content is done once after the client is initialized and an ‘ajax’ request is made to fetch the contents of the currently selected article and the content is painted on the DOM later. The knowledge base was loaded based on the below steps.
- User opens a URL Eg: [https://docs.document360.com/docs/december-2023]
- The overall layout of the page is rendered on the server
- The server returns the overall rendered layout page along with some data that is required for doing some rendering on the client.
- Once the layout is initialized the client sends a request to the server to fetch content for the current article, the network request URL looks like this ‘{subDomain}/load-article/{slug}’
- To give a more exact example, the URL might look like this https://docs.document360.com/docs/december-2023

This is the same URL a google bot will crawl, but it was not able to find the content of the article because google does not know that we load the content via a sub nested route ‘load-article’. So, this is obvious that this is a fundamental problem and has a massive impact on our SEO. This led to a couple more issues
- Duplicate results on Google Search
- Google cached content is empty
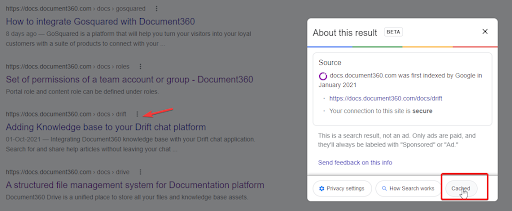
When we viewed the ‘cached’ page of the public site, it was just empty. So, we ventured out on an optimal and strong solution that will improve our SEO score as well as not lead to any more problems in the future.
Here’s how we solved the problem:
We were still convinced that we should not reload the entire page when the user switches between articles from the category tree, so we anyway had to make an ‘ajax’ call. But we need the content to be painted without painting the entire page.
Let us imagine two scenarios:
- A user visits the page and reads the articles by navigating the tree
- A bot or spider crawling the page on the links
Also Read: How to SEO Your Knowledge Base Articles
Scenario 1: User visits a page
When a user is visiting the page, as mentioned above we should only paint the content on navigating between articles. But the same is not true for case 2, when a bot visits a URL, it just needs to crawl through the content, it does not care or know whether we paint the content again or not.
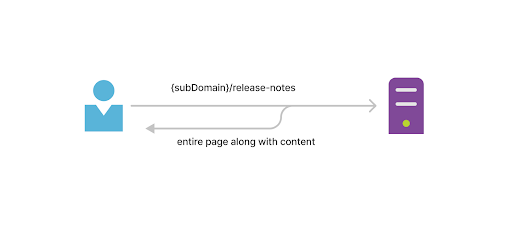
A better example to understand it better. From a user perspective, when a user browses through articles, we remove the nested route called ‘ load-article’ and just initiate a request to the actual URL with some additional query parameters to inform the server that this request is initiated by a user.
The URL looks like this ‘{subDomain}/release-notes/?partialView=on’. Google will consider a URL with and without parameters as two different URLs. To resolve the problem, we added a canonical tag so Google will ignore the URL with query parameter [More Reference on Google Docs].
A site can have query params to preserve the state etc. So, when this request hits the server, the server responds with only the content. The content block once received will be painted on the client.
Scenario 2: Bot visits a page
When a bot visits the page, we render the entire content of the page on the server. When a bot visits a page, it only knows the URL of the content directly via the sitemap.

Final words
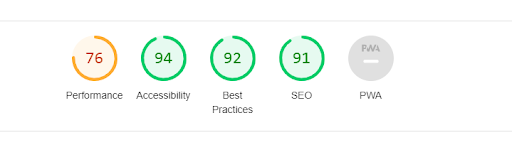
We deployed this solution and we observed it for a couple of weeks internally and found that this approach works better and improved our metrics measured via Google Lighthouse.
Before
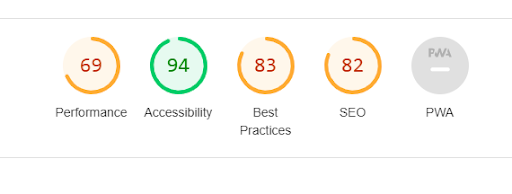
After
If you are interested in more in-depth research on the workings of SEO, you can check out the references below.

